General Number Field Sieve (GNFS): Họ đã phá RSA thế nào?
Motivation
Nếu mình đưa cho bạn hai số nguyên tố lớn và , việc tính tích chỉ mất vài micro giây trên bất kỳ máy tính nào. Nhưng nếu mình đưa cho bạn số và yêu cầu tìm ngược lại và , bạn đang đối mặt với một bức tường thép đã bảo vệ nền tài chính và dữ liệu toàn cầu trong hơn 4 thập kỷ qua. Ví dụ, chúng ta có thể tính trong tích tắc, nhưng nếu hỏi rằng có thể phân tích thành mấy nhân với mấy thì rất khó trả lời.
Hệ thống mật mã RSA – thứ đang bảo mật các giao dịch ngân hàng, chữ ký số và kết nối HTTPS của bạn – dựa hoàn toàn vào giả định rằng việc phân tích một số nguyên cực lớn (khoảng 2048-bit trở lên) là bất khả thi trong thời gian thực. Tuy nhiên, "bất khả thi" là một khái niệm mang tính thời điểm. Từ những phương pháp thô sơ ban đầu bằng cách bruteforce đơn giản (thử lần lượt lấy số đã cho chia cho cho đến khi tìm ra kết quả), các nhà toán học đã không ngừng tìm kiếm những "vết nứt" trên bức tường RSA. Trong những nỗ lực tìm kiếm ấy, nhân loại đã tìm ra một số thuật toán quan trọng để giải quyết vấn đề này:
Trial Division: Chỉ hiệu quả với các số rất nhỏ.
Pollard's rho: Tốt để tìm các nhân tử nhỏ
Quadratic Sieve (QS): Từng là "ông vua" tốc độ vào những năm 1980, hoạt động dựa trên việc tìm các số chính phương modulo .
Khi các phương pháp truyền thống như Quadratic Sieve (Sàng bình phương) bắt đầu chạm ngưỡng giới hạn với các số nguyên trên 100 chữ số, cộng đồng toán học cần một công cụ mạnh mẽ hơn. Đó là lúc General Number Field Sieve (GNFS) ra đời. Khác với những người tiền nhiệm, GNFS không chỉ loanh quanh trong tập số nguyên thông thường. Nó thực hiện một cú nhảy vọt về tư duy: Chuyển bài toán từ tập số nguyên sang các trường số đại số (Algebraic Number Fields). Bằng cách xây dựng các đa thức phức tạp và làm việc trong không gian đa chiều của lý thuyết số, GNFS đã đạt được một kỳ tích: Biến tốc độ phân tích từ hàm mũ (exponential) – vốn cực chậm – thành hàm siêu đa thức dưới mức mũ (sub-exponential). Nói cách khác, GNFS đã thu hẹp khoảng cách giữa cái "không thể" và cái "có thể", trở thành thuật toán nhanh nhất thế giới hiện nay để bẻ khóa các mã khóa RSA có độ dài tổng quát.
Ý tưởng cốt lõi
Mọi thuật toán phân tích thừa số hiện đại, bao gồm cả GNFS, thực chất đều "đứng trên vai" một ý tưởng đơn giản của nhà toán học Pierre de Fermat từ thế kỷ 17.
Để phân tích một số lẻ thành nhân tử, mục tiêu của chúng ta là tìm hai số và sao cho:
Điều này tương đương với:
Nếu , thì phải chia sẻ các nhân tử chung với và . Khi đó, ta chỉ cần dùng thuật toán Euclid để tính:
Nếu , chúc mừng, bạn đã tìm được một nhân tử của .
Nếu hoặc , đây là trường hợp 'xấu' (), ta phải chọn tập hợp các quan hệ khác từ bước Đại số tuyến tính để thử lại.
Trong một số ít trường hợp, ta tìm được hoặc . Khi đó sẽ trả về hoặc , không giúp ích gì cho việc phân tích. GNFS (và các thuật toán dạng Sieve) được thiết kế để tạo ra nhiều cặp khác nhau, đảm bảo xác suất thành công sau vài lần thử là cực lớn (thường là cho mỗi cặp).
Thuật toán Sàng Bình Phương (Quadratic Sieve - QS)
Trước khi đi vào thuật toán GNFS, chúng ta nên tìm hiểu thuật toán Sàng Bình Phương - QS vì đây chính là ý tưởng cốt lõi của GNFS. Mục tiêu của QS là tìm ra hai số sao cho:
Vì nếu điều này xảy ra thì chia hết cho và ta có cơ hội cao tìm được nhân tử bằng cách tính .
Định nghĩa số mượt (Smooth number):
Một số nguyên được gọi là -mượt nếu mọi ước nguyên tố của nó đều thỏa mãn .
Ví dụ: Với ngưỡng :
Số là số 10-mượt (vì 2 và 3 đều < 10).
Số không là số 10-mượt (vì có ước 11 > 10).
Mục tiêu của chúng ta là tạo ra một số chính phương . Một số là chính phương khi và chỉ khi tất cả số mũ trong phân tích thừa số nguyên tố của nó đều là số chẵn. Nếu chúng ta có một tập hợp các số mượt, việc biến tích của chúng thành một số chính phương trở thành một bài toán giải hệ phương trình (Đại số tuyến tính) trên các số mũ modulo 2. Điều này dễ hơn rất nhiều so với việc mò mẫm ngẫu nhiên.
Có một quy luật bất biến trong lý thuyết số: Số càng nhỏ thì xác suất nó là số mượt càng cao. Hãy tưởng tượng bạn đang tìm các số mượt với ngưỡng :
Nếu bạn chọn một số ngẫu nhiên có 100 chữ số, xác suất để nó chỉ chứa các ước nguyên tố nhỏ hơn 100 là cực kỳ thấp (gần như bằng 0).
Nếu bạn chọn một số chỉ có 10 chữ số, xác suất tìm thấy số mượt sẽ tăng lên hàng triệu lần.
Để thuật toán chạy nhanh, ta phải tìm cách tạo ra các số có độ lớn tối thiểu. Số càng nhỏ, ta càng mau chóng thu thập đủ "nguyên liệu" (các số mượt) để ghép thành bình phương .
Thuật toán QS:
Để tìm , ta cần là kết quả của một tích các số mượt. QS chọn các số có dạng:
Lý do là vì:
Tự động thỏa mãn điều kiện Modulo: Gọi . Ta luôn có . Vế trái () đã là một bình phương hoàn hảo. Ta chỉ cần "ép" vế phải thành bình phương nữa là xong.
Tối ưu hóa độ lớn (The "Smallness" trick): Đây chính là lý do ta chọn .
Nếu chọn ngẫu nhiên, sẽ dễ lớn xấp xỉ .
Nhưng vì , nên khi trừ đi , hiệu số sẽ rất nhỏ (chỉ xấp xỉ ).
Sau khi đã có hàm "tạo số nhỏ" , chúng ta sẽ thực hiện quy trình sau:
Bước 1: Thiết lập Cơ sở thừa số (Factor Base)
Chúng ta chọn một ngưỡng và tập hợp tất cả các số nguyên tố . Đây chính là "lưới lọc" của chúng ta (Factor Base).
Bước 2: Giai đoạn Sàng (Sieving) – Đi tìm các số mượt
Sau khi đã có hàm và Factor Base (Cơ sở thừa số), chúng ta bắt đầu quy trình lọc tìm số mượt qua các tiểu bước sau:
Trước khi bắt đầu "sàng", máy tính cần chuẩn bị một dải các ứng viên. Chúng ta xác định một khoảng giá trị của (ví dụ từ đến ) và tính toán một loạt các giá trị tương ứng.Các giá trị này được nạp vào một mảng (array) trong bộ nhớ. Đây chính là "nguyên liệu thô" mà chúng ta sẽ đưa qua các lớp lưới lọc ở bước kế tiếp.
Tiếp theo, thay vì lấy từng số trong mảng ra để chia thử (rất chậm), thuật toán tận dụng một tính chất toán học: Nếu chia hết cho một số nguyên tố , thì các giá trị tiếp theo như cũng sẽ chia hết cho . Ý tưởng này gióng hệt như Sàng Erathostene.
Quy trình thực hiện "Lọc" với mỗi số nguyên tố trong Factor Base:
Tìm vị trí đầu tiên mà .
Nhảy: Cứ cách ô, ta lại thực hiện chia giá trị tại ô đó cho (chia cho đến khi không chia được nữa).
Sau bước lọc, máy tính sẽ trả về một danh sách các cặp quan hệ thỏa mãn:
Trong đó đều nằm trong Factor Base mà bạn đã chọn ban đầu.
Bước 3: Chọn lọc để ghép bình phương
Mục tiêu của bước này là chọn ra một tập hợp các số mượt sao cho khi nhân tất cả chúng lại, ta được một số mà tất cả các số mũ của các thừa số nguyên tố đều là số chẵn.
Giả sử Factor Base của chúng ta là . Với mỗi số mượt tìm được, ta không quan tâm giá trị tuyệt đối của số mũ, ta chỉ quan tâm nó là Chẵn (0) hay Lẻ (1).
Ví dụ 1: Vector số mũ là .
Chuyển sang Modulo 2: .
Ví dụ 2: Vector số mũ là .
Chuyển sang Modulo 2: .
Chúng ta xếp tất cả các vector nhị phân này thành các dòng của một ma trận:
Cột: Đại diện cho các số nguyên tố trong Factor Base.
Dòng: Đại diện cho từng số mượt mà ta nhặt được.
Bài toán bây giờ trở thành: Tìm một tổ hợp các dòng sao cho tổng của chúng (theo Modulo 2) bằng vector không vì tổng bằng 0 modulo 2 nghĩa là ở mỗi cột (mỗi số nguyên tố), tổng các số mũ là một số chẵn. Mà tích các số có số mũ chẵn thì chắc chắn là một Bình phương hoàn hảo.
Ví dụ: Giả sử sau bước Sàng, ta có 3 số mượt:
(tương ứng )
(tương ứng )
(tương ứng )
Ma trận được tạo thành sẽ là:
Dễ dàng thấy rằng nếu ta cộng cả 3 dòng này lại:
Như vậy, nếu ta nhân , ta sẽ được một bình phương hoàn hảo .
Với các số RSA lớn, ma trận này có thể lên tới hàng triệu dòng và cột. Việc giải bằng phương pháp khử Gauss (Gaussian Elimination) thông thường sẽ rất chậm. Thay vào đó, các siêu máy tính sử dụng các thuật toán tối ưu hơn cho Ma trận thưa (Sparse Matrix) như:
Thuật toán Block Lanczos
Thuật toán Wiedemann
Đây là những "con quái vật" về tốc độ, giúp tìm ra lời giải (tổ hợp các dòng) chỉ trong thời gian ngắn.
Bước 4: Tìm nhân tử (GCD)
Đây là bước chúng ta hiện thực hóa mục tiêu ban đầu: Biến đẳng thức modulo thành các nhân tử thực sự của .
Từ kết quả của Bước 3, giả sử chúng ta tìm được tập hợp các chỉ số sao cho tích các dòng tương ứng trong ma trận bằng . Ta tính hai giá trị sau:
Tính : Là tích của các số (với ) đã dùng để tạo ra các số mượt đó.
Tính : Là căn bậc hai của tích các số mượt . Vì tích này chắc chắn là bình phương hoàn hảo (do các số mũ đều chẵn), ta tính:
Với chính là tổng số mũ của số nguyên tố thứ trong tích của tất cả các số mượt mà chúng ta đã chọn.
Lúc này, theo đúng thiết lập của hàm , chúng ta đã có:
Chúng ta không cần biết phân tích thành gì, chỉ cần dùng thuật toán Euclid để tìm ước chung lớn nhất:
Nếu , thì chính là một nhân tử không tầm thường của . Bài toán được giải.
Nếu hoặc , nghĩa là chúng ta rơi vào trường hợp thì chúng ta quay lại Bước 3 để tìm tổ hợp khác.
Demo thuật toán QS
Tại sao cần GNFS?
Như bạn đã thấy ở các phần trước, hiệu quả của QS phụ thuộc vào độ lớn của hàm .
Trong QS, .
Khi có 200 chữ số, có tận 100 chữ số. Việc tìm một số mượt trong khoảng 100 chữ số vẫn là một thử thách quá lớn đối với máy tính hiện nay.
Từ QS đến GNFS
Cốt lõi của cả hai vẫn là đi tìm: . Nhưng sự khác biệt nằm ở chỗ chúng ta tìm các "số mượt" ở sư khác biệt về chiến thuật:
Với QS: Bạn chỉ đi trên một con đường thẳng (số nguyên ). Bạn tìm số mượt có độ lớn xấp xỉ .
Với GNFS: Bạn xây dựng một "cây cầu" nối giữa hai thế giới: Thế giới Hữu tỉ (số nguyên) và Thế giới Đại số (trường số phức tạp hơn). Nhờ cây cầu này, bạn chỉ phải tìm các số mượt có độ lớn xấp xỉ (với thường bằng 5 hoặc 6).
Ý tưởng của GNFS
Như bạn đã thấy ở phần Quadratic Sieve (QS), hiệu quả của thuật toán phụ thuộc rất lớn vào kích thước của hàm . Trong QS, . Khi có 200 chữ số, vẫn còn khoảng 100 chữ số – một con số quá lớn để dễ dàng tìm được các số mượt (smooth numbers).
GNFS giải quyết vấn đề này bằng một ý tưởng thông minh:
Thay vì làm việc trực tiếp với các số cỡ , chúng ta dùng một đa thức bậc cao để “kéo” kích thước của các số cần sàng xuống chỉ còn khoảng (với thường là 5 hoặc 6). Với 200 chữ số, chỉ còn khoảng 40 chữ số. Xác suất tìm thấy số mượt trong khoảng 40 chữ số cao hơn hàng tỷ lần so với 100 chữ số. Đó chính là lý do GNFS trở thành vua của việc phân tích thừa số.
Xây dựng hai thế giới song song
Để làm được điều này, GNFS tạo ra hai thế giới hoạt động cùng lúc:
Thế giới hữu tỉ (Rational side): Chính là tập hợp các số nguyên quen thuộc.
Thế giới đại số (Algebraic side): Vành số nguyên , trong đó là một nghiệm của đa thức mà chúng ta chọn.
Hai thế giới này được nối với nhau bởi một ánh xạ đồng cấu :
Quy tắc cực kỳ đơn giản: Ở đâu có , hãy thay bằng (một số nguyên ta chọn). Ví dụ:
Tính chất quan trọng nhất của là bảo toàn phép nhân:
Nhờ đó, mọi phép tính phức tạp ở thế giới đại số đều có thể “nhảy” về thế giới hữu tỉ một cách nhất quán.
Chọn đa thức và số (Base- method)
Chúng ta chọn một đa thức bậc (thường hoặc ) có hệ số nhỏ, sao cho tồn tại số nguyên thỏa mãn:
Cách chọn phổ biến nhất (Base-):
Chọn
Viết dưới dạng cơ số :
Khi đó đa thức chính là:
Lúc này , nên , và là nghiệm của , tức .
Phía hữu tỉ (Rational Side) – Giống QS
Ta xét các số nguyên . Mục tiêu là tìm một tập hợp các cặp sao cho tích của chúng là một bình phương:
Đây chính là bài toán sàng số mượt quen thuộc trong QS.
Phía đại số (Algebraic Side)
Ở đây ta xét các phần tử . Ta muốn tích của chúng cũng là một bình phương trong :
Vấn đề: không phải số nguyên thông thường, nên ta không thể factor trực tiếp như trong .
Giải pháp: Sử dụng Norm và Prime ideals.
Norm của là một số nguyên được định nghĩa bằng:
Ví dụ với , và thì:
Norm có tính chất nhân rất đẹp: . Nếu là số mượt (chỉ gồm thừa số nguyên tố nhỏ), thì được coi là “đủ mịn” ở phía đại số.
Prime Ideals
Trong , khái niệm “số nguyên tố” được thay bằng prime ideal . Mỗi prime ideal nằm “trên” một số nguyên tố trong và có norm (thường là hoặc ).
Analog dễ hình dung:
Trong : factor base là tập các số nguyên tố nhỏ.
Trong : factor base algebraic là tập các prime ideals có norm nhỏ.
Khi factor hoàn toàn thành các số nguyên tố nhỏ, ta có thể ánh xạ ngược lại thành tích của các prime ideals nhỏ.
Tại sao phải dùng prime ideals?
Vì trong vành , ta có định lý phân tích duy nhất the prime ideal. Nghĩa là mọi phần tử không-zero đều có thể phân tích thành tích của các prime ideal một cách duy nhất (tính đến đơn vị). Do đó, thay vì nói “ được phân tích thành thừa số nào”, ta nói: " thuosc tích của một số prime ideal có norm nhỏ".
Ví dụ với , khi ta tính , số 7 trên phía hữu tỉ tương ứng với một (hoặc vài) prime ideals nằm trên ở phía đại số, với . Tương tự, khi , ta ánh xạ thành tích của các lý tưởng nguyên tố tương ứng với 3, 5, 7.
Nói chung, vài trò của prime ideals ho phép chúng ta xây dựng một “từ điển” chung giữa hai thế giới:
Phía hữu tỉ: dùng số nguyên tố thông thường.
Phía đại số: dùng lý tưởng nguyên tố có norm nhỏ.
Khi thu thập đủ relations, ta sẽ có một ma trận chứa cả hai loại “thừa số” này. Bước đại số tuyến tính sau đó tìm một tổ hợp tuyến tính (mod 2) sao cho tổng số mũ của mọi số nguyên tố và mọi lý tưởng nguyên tố đều chẵn → cả hai phía đều trở thành bình phương.
Tóm tắt ý tưởng then chốt:
Ta sàng tìm các cặp sao cho:
Phía rational: là smooth theo số nguyên tố.
Phía algebraic: là smooth theo prime ideals.
Khi thu thập đủ nhiều cặp như vậy, bước đại số tuyến tính sẽ tìm một tổ hợp (mod 2) làm cho tích ở cả hai phía đều trở thành bình phương.
Kết nối hai phía → Phá RSA
Nhờ tính đồng cấu của , khi cả hai phía đều là bình phương, ta có:
Với . Lúc này sẽ cho ta hai thừa số không tầm thường của . Đó chính là cách GNFS “phá” RSA.
Quy trình 4 bước của thuật toán GNFS
Bước 1: Chọn đa thức (Polynomial Selection)
Trong QS, hàm rất đơn giản. Trong GNFS, đây là bước quan trọng nhất:
Ta chọn một đa thức bậc và một số sao cho .
Việc này thiết lập nên Tính Đồng cấu: Ở đâu có nghiệm của đa thức, ta có thể thay bằng số nguyên khi xét modulo .
Bước 2: Sàng (Sieving) - Từ đường thẳng lên mặt phẳng
QS: Sàng trên một dãy số để tìm mượt.
GNFS: Sàng trên một mặt phẳng tọa độ . Chúng ta đi tìm các cặp sao cho cả hai bên cầu đều mượt:
Phía Hữu tỉ: là số mượt.
Phía Đại số: là "số mượt" (trong trường đại số).
Bước 3: Đại số tuyến tính (Linear Algebra)
QS: Ma trận chỉ chứa các số nguyên tố nhỏ.
GNFS: Ma trận phức tạp hơn gấp đôi vì nó phải chứa cả các số nguyên tố thường (hữu tỉ) và các "lý tưởng nguyên tố" (phía đại số).
Mục tiêu: Vẫn là tìm một tổ hợp các cặp sao cho tích của chúng tạo ra bình phương ở cả hai phía.
Bước 4: Khai căn và GCD (Square Root & GCD)
QS: Khai căn tích các số nguyên (rất dễ).
GNFS: Phía hữu tỉ thì dễ, nhưng phía đại số bạn phải khai căn một tích các phần tử . Vì tích này cực kỳ lớn, ta phải dùng các thuật toán chuyên sâu để tìm căn bậc hai mà không cần nhân trực tiếp.
Kết thúc: Khi đã có (hữu tỉ) và (đại số), ta tính:
Ví dụ thực tiễn
Gia sử ta muốn factor với factor base
Bước 1: Polynomial selection
Chọn
Chọn vì
Bước 2: Sieving
Giờ ta xét các cặp ví dụ: ta có:
smooth!
Ta có và là nghiệm của nên . Vậy smooth!
Vậy ta có 1 relation hợp lệ:
Bước 3: Linear algebra
Giả sử sau khi tìm kiếm ta tìm thêm được 4 relation sau (cả rational và algebraic đều smooth):
Relation | Rational | Algebraic Norm | ||
|---|---|---|---|---|
1 | 11 | 1 | ||
2 | -18 | 1 | ||
3 | -17 | 1 | ||
4 | -12 | 1 | ||
5 | -11 | 1 |
Sau khi giải hệ tuyến tính mod 2 (Gaussian elimination hoặc Block Lanczos trong thực tế), ta tìm được một dependency: sử dụng Relation 2, 3, 4 và 5. Kết quả là:
Tích các giá trị rational side là một bình phương .
Tích các Norm (algebraic side) là một bình phương trong vành
Bước 4: Từ dependency trên ta tính
(phía hữu tỉ).
(phía đại số).
(ánh xạ đồng cấu về ).
Kết quả thu được trong ví dụ này:
Kiểm tra:
Suy ra và .
Tính gcd:
Vậy . Thuật toán GNFS thành công!
Để dễ hình dung, bạn có thể chơi với demo tiếp theo nhé.
Demo cho GNFS
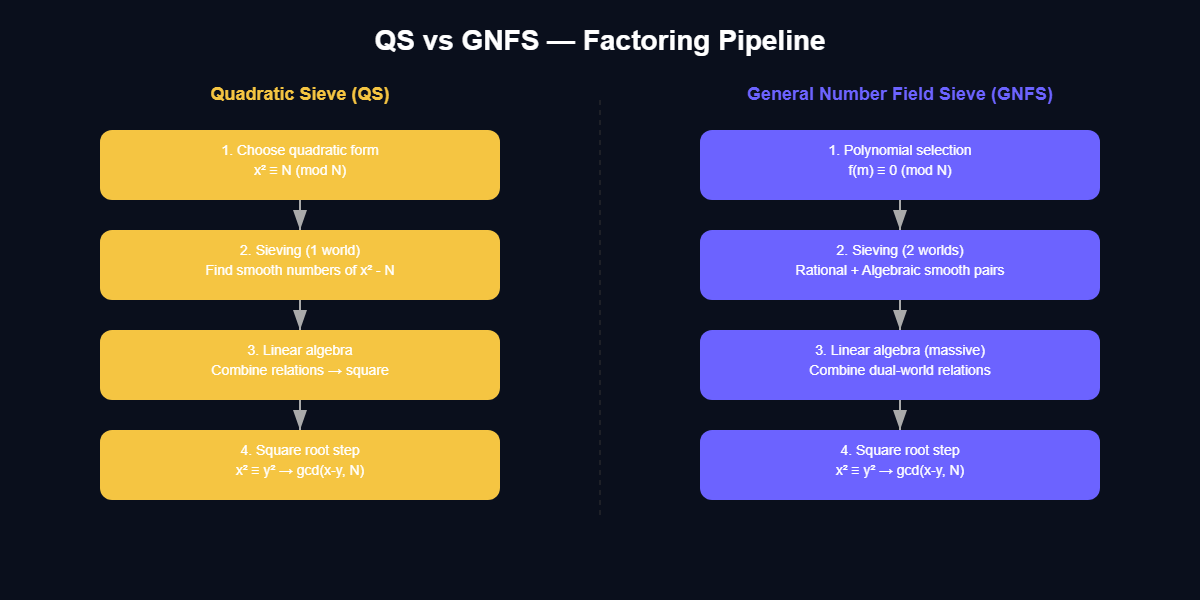
Bảng so sánh các bước giữa QS và GGFS
Cuối cùng, hãy cùng nhìn lại bảng so sánh các bước giữa 2 thuật toán QS và GNFS
More from Cryptography & Blockchain
- Scalable Distributed Verifiable RNG
- Verifiable Random Function (VRF) và một ví dụ đơn giản
- Multi Party Computing với đồng cấu Paillier
- Lattice-based Post-Quantum Cryptography - Hệ mật mã hậu lượng tử trên dàn
- Thuật toán Euclide mở rộng
- Shamir's Secret Sharing: Kho báu của tên cướp và Alibaba
- ECDSA - Chữ ký số trên đường cong elliptic
- Elliptic Curve trên Trường Hữu Hạn
- RSA - Kỹ thuật mã hóa khóa công khai
- Miller-Rabin Primality Test
- Thuật toán AKS - Kiểm tra số nguyên tố thời gian đa thức
- Chữ ký số trong hệ RSA
- ZKP - Giới thiệu đơn giản về Chứng minh Không Để Lộ Tri Thức
- Quadratic Arithmetic Program (QAP) - Interactive Demo
- Rank-1 Constraint System (R1CS) - Interactive Demo
- Fiat-Shamir Heuristic - Mô hình Non Interactive ZK đơn giản
- Diffie-Hellman Key Exchange - Giao thức trao đổi khóa
- Bloom Filter
- Elliptic curve trên trường số thực
- Zero Knowledge Proof với KZG commitment scheme
- Một vài chú giải về "The Tuyen Optimization"
- Khám phá Timebased OTP
- Proof-Of-Work Concensus Demo
- Merkle Tree
Comments
No comments yet. Be the first to comment!